Convolutional Neural Networks For Artificial Vision

What is Traditional Machine Learning?
You may think that the AI and ML ( Artificial Intelligence & Machine Learning ) are very modern state of the art subject. But it is not. The history of machine learning goes back as far as the history of computer technology. In 1652 Blaise Pascal while a 19-year-old teenager created an arithmetic machine that could add subtract multiply and divide.
In 1951 Marvin Minsky with the help of Dean Edmonds created the first artificial neural network. it was called Snarc(Stochastic neural analog reinforcement calculator). In 1952 Arthur Samuel begins working on some of the first machine learning programs at IBM’s Poughkeepsie laboratory.
So what is Machine learning ? Following is the basic definition.
Basic Definition : Algorithms which analyze data, learn from it and make informed decisions based on the insights learned.
Machine learning is contributing to a variety of automated activities. It affects virtually every industry — from scanning for IT security malware to weather forecasting, to stockbrokers looking for cheap trades. Traditional machine learning requires complex math and a lot of coding for the desired functions and tests to eventually be achieved.
Training of machine learning algorithms on large amounts of data is necessary. The more data the algorithm receives, the better it gets.
Traditional machine learning is a pretty old field and uses methods and algorithms which have been around for dozens of years, some of them as early as the sixties.
These classic algorithms include such algorithms as the so-called Naïve Bayes Classifier and Support Vector Machines. Both are widely used in data classification.
In addition to the classification, there are also algorithms for cluster analysis, such as the well-known K-Means and the tree based clustering. Machine learning uses approaches such as principal component analysis and t-SNE to reduce the dimensionality of the data and gain more insight into its existence.
Deep Learning
Deep learning is a branch of machine learning. It is a discipline focused on learning by studying computer algorithms, and evolving on its own. Though machine learning uses simpler principles, deep learning works with artificial neural networks, designed to mimic how people think and learn. Neural networks had been constrained by computing power until recently and were therefore limited in complexity. Nevertheless, advances in big data analytics have allowed for larger, sophisticated neural networks, allowing computers to analyze, learn and respond faster than humans to complex situations. Deep learning has helped to identify pictures, to translate languages and to understand speech. It can be used to solve any problem about pattern recognition without human intervention.
Artificial neural networks, which consist of many layers, are driving deep learning. Deep Neural Networks (DNNs) are types of networks where each layer can perform complex operations such as image, sound and text representation and abstraction. Considered the fastest-growing machine learning area, deep learning represents a profoundly transformative digital technology, and increasing numbers of businesses are using it to develop new business models.
How Does Deep Learning Works ?
Neural networks consist of layers of nodes, similar to the neurons that make up the human brain. Nodes are linked to adjacent layers within individual layers. It’s said the network is better based on the amount of layers it has. Within the human brain, one single neuron receives thousands of signals from other neurons. Signals pass between nodes within an artificial neural network, and allocate corresponding weights. A heavier weighted node on the next layer of nodes will have more effect. The final layer will compile weighted inputs to generate an output. Deep learning systems require powerful hardware because they process a large amount of data and involve multiple complex mathematical calculations. Nevertheless, even with such advanced hardware, computations for profound learning will take weeks.
Deep learning systems require large amounts of data for accurate results to be returned; thus, information is fed as huge data sets. Artificial neural networks can classify data with the answers obtained from a series of binary true or false questions which require highly complex mathematical calculations(eg : high order derivatives with multivariate calculus ) when processing the data. For example, a system of facial recognition works by learning to identify and recognize edges and lines of faces, then more important parts of faces, and finally, overall facial representations. The software trains itself over time and the probability of appropriate answers increases. The facial recognition system in this case will accurately identify faces over time.
Different Types Of Neural Networks In Deep Learning ?
There are three important types of neural networks that form the basis for most pre –trained in training.
· Traditional Artificial Neural Network (ANN)
· Convolution Neural Network (CNN)
· Recurrent Neural Network (RNN)
What Is Artificial Neural Network (ANN) And Why Should We Use It ?
Artificial Neural Network, or ANN, is a multi-layered network of perceptrons / neurons. ANN is also known as a Feed-Forward Neural network, because inputs are processed only in the direction of forward:
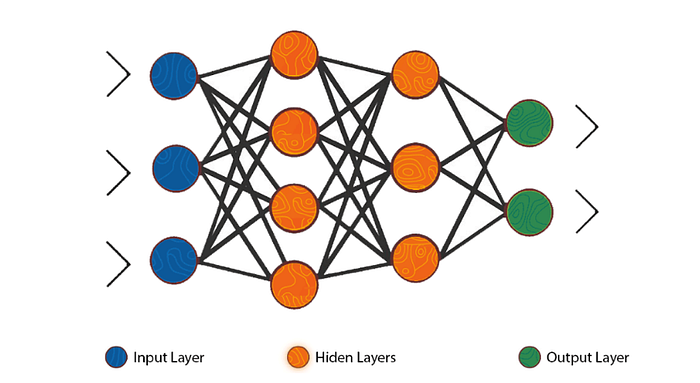
As you can see, ANN is made up of 3 layers — Input, Hidden and Output. The input layer accepts the inputs, the inputs are processed by the hidden layer and the output layer produces the result. Essentially, each layer tries to learn some weights.
ANN can be used to solve:
· Tabular data
· Image data
· Text data
Advantages Of Artificial Neural Network (ANN)
Artificial Neural Network has the ability to learn any nonlinear task. These networks are thus popularly referred to as Universal Task Approximators. ANNs have the ability to learn weights which map any output data.
Activation function is one of the principal reasons behind universal approximation. Activation functions incorporate nonlinear network properties. This lets the network learn about any dynamic input-output relationships.
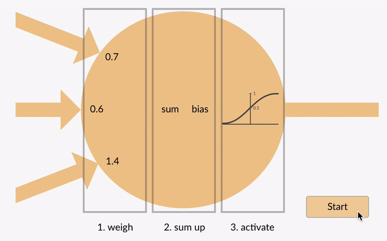
As you can see here, the output is the activation of a weighted input total at each neuron. But if there is no activation function means that the network is only learning the linear structure and will never be able to learn complex relations.
“ An activation function is a powerhouse of ANN “
Challenges With Artificial Neural Network (ANN)
While solving an issue of image classification using ANN, the first step is to transform a 2-dimensional image into a 1-dimensional vector before the model is equipped.
That has two disadvantages to it:
· The number of trainable parameters dramatically increases with an increase in image size
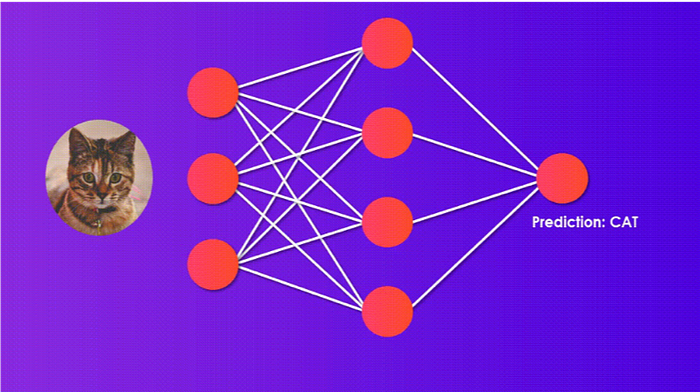
In the above case, if the image size is 224 * 224, then the number of trainable parameters with only 4 neurons at the first hidden layer is 602,112.
· ANN loses an image’s spatial characteristics. Spatial characteristics refer to pixel arrangement in an image.
One common problem in here is the Gradient Fading and Exploding. The backpropagation algorithm associates this problem. Using this backpropagation algorithm the weights of a neural network are modified by finding the gradients:
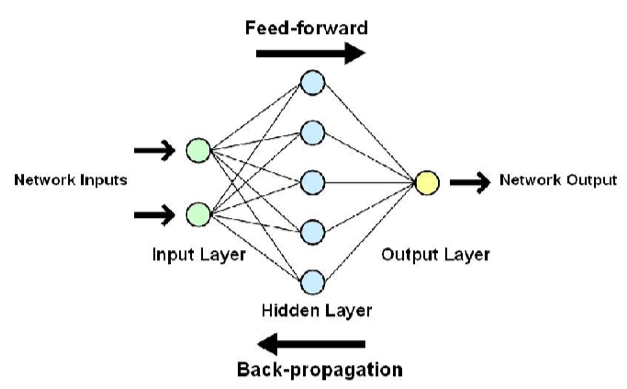
Therefore, in the case of a very deep neural network (network with a large number of hidden layers), the gradient disappears or bursts as it propagates backwards, resulting in a gradient disappearing or exploding.
· ANN can not capture sequential information required to handle sequence data in the input data
Why Is It Hard To Do Vision Related Problems Using Traditional Machine Learning ?
In automated visual inspection systems offer manufacturers the ability to monitor and respond in real time to production problems, reduce costs and improve quality. Most visual inspection systems nowadays consist of some form of hardware for image capture, and an integrated or discrete device equipped with specialized image processing software. At the heart of this program is a computer vision algorithm which encompasses the array of numbers representing the product picture, performs some mathematical operations on those numbers, and calculates a final result. For example, the computer vision algorithm can determine that a whole product is defective, detect the type and position of a defect on a product, test for the existence of some subcomponent, or calculate the overall finish quality. Driver-less cars also features high artificial vision as one of their key inputs.
This computer vision algorithm is divided into two stages in traditional machine vision systems. A series of mathematical operations are performed on the image’s raw pixel values in the first step, which is usually called feature extraction. For example, when searching for defects in a product image, the feature extraction step may consist of sliding a small window over the entire image, and computing the contrast for the pixels within the window for each window position-the difference between the brightest and darkest pixels. This feature may be useful in making a final determination, since higher-contrast windows may be more likely to contain defects.
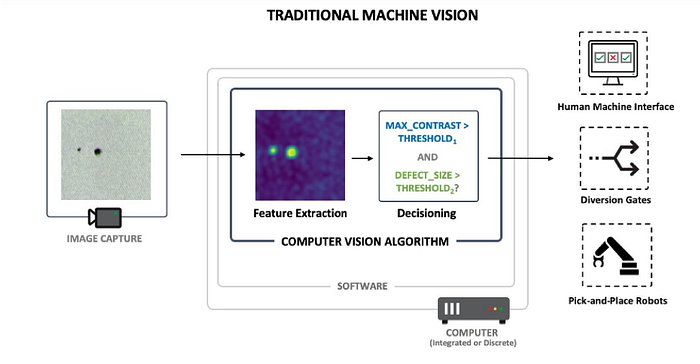
The functions computed in the first step are combined in the second and final processing step to make a final decision about the image. A combination of manually calibrated parameters or thresholds is often used to accomplish this decisioning step. For example, if any window contains contrast greater than ten, our computer vision algorithm can flag an image as defective.
Now, as you can imagine, in some cases this strategy can work well but in others it can fail. Not every region of a picture with high contrast represents a defect. Such types of errors also result in high false positive levels, where machine vision systems flag as faulty good products. Many devices use many different types of features to alleviate such issues, in an attempt to differentiate fine grains. This strategy can lead to better results, but it does come with real cost. Hundreds of features mean lots of tuning parameters or thresholds, making it difficult for these devices to adapt to changing conditions on the factory floor, even for the most skilled operators and engineers.
So this two-step approach to feature extraction accompanied by decision making, which is at the core of many machine vision systems, can be very difficult to deploy and manage effectively in practice.
Today, as you can imagine, this is not just a manufacturing problem-this two-step solution also exists in many other computer vision applications, and researchers have been searching for a more reliable and efficient way forward for decades.
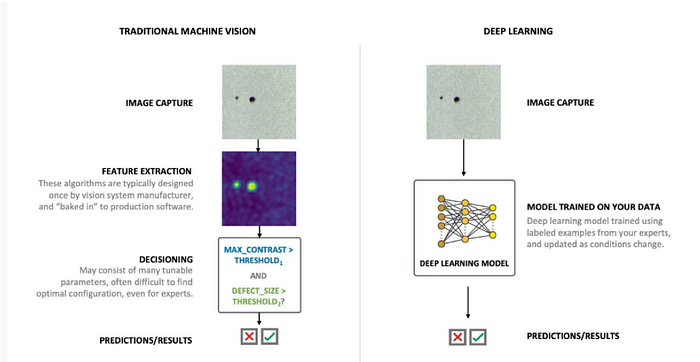
An interesting alternative solution is to replace the two-stage pipeline with a single unified process capable of extracting features from our images as well as making decisions. Of course, if we set out to design or engineer such a single model, we can end up right back where we started, with two distinct steps.
Then, in 2012, researchers at the University of Toronto published groundbreaking work showing how a neural network that was deep in many layers could be successfully trained on a large-scale dataset for the first time. Unfortunately no one really understood how to do this for most of the history of computer vision.
Researchers came close in the 1980s and 1990s, designing computational models called neural networks; but even as recently as 2010, it wasn’t really clear whether these models were able to solve the types of general computer vision problems that we really care about.
This systematic approach to learning is called deep learning, and has fully revolutionized the world of computer vision over the last few years. For example, on the demanding ImageNet image classification benchmark, deep learning based approaches lowered the error rate from about 30 per cent in 2012 to less than 4 per cent in 2015 — achieving super-human image classification efficiency across the 1000 distinct image classes of the task.
What Is Convolutional Neural Network:The Big Picture ?
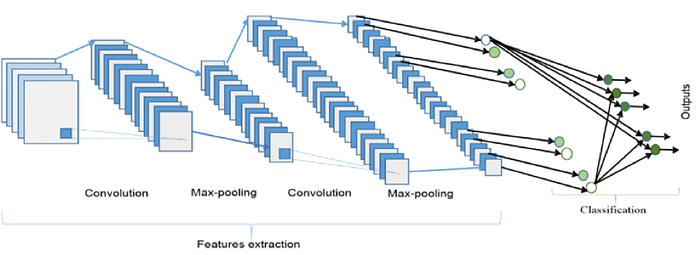
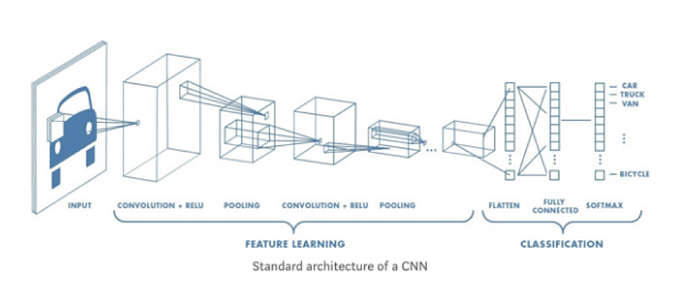
Convolutional Neural Network (CNN) is a type of deep learning model for data processing that has a grid pattern, such as images that are inspired by animal visual cortex organization and designed to learn feature hierarchies from low to high-level patterns automatically and adaptively. CNN is a mathematical construct usually consisting of three types of layers (or building blocks): convolution, pooling, and layers which are fully linked. The first two, convolution and pooling layers, perform extraction characteristics while the third, a fully connected layer, maps the characteristics extracted into final production, such as classification. A convolution layer plays a key role within CNN, which consists of a stack of mathematical operations, such as convolution, a specific linear operation sort. Pixel values are contained in a two-dimensional (2D) grid in digital images, i.e., a number array (Fig. 8), at each image location, a small grid of parameters called the kernel, an optimizable extractor function, is added, making CNNs highly efficient for image processing, as a feature can occur anywhere on the image. As one layer feeds its output into the next layer, features extracted can become more complex, both hierarchically and gradually. The method of optimizing parameters such as kernels is called preparation, which is performed to reduce, among others, the difference between outputs and ground truth labels by means of a backpropagation algorithm and gradient descent optimization.
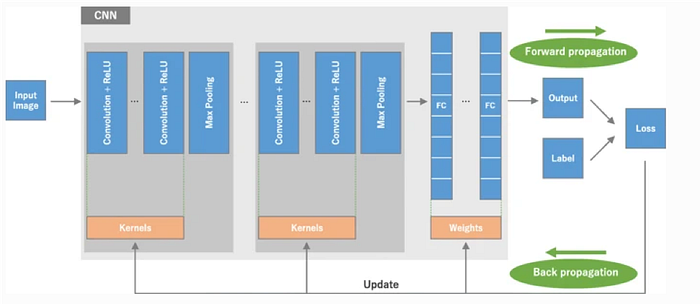
A CNN consists of a stacking of several building blocks: convolution layers, pooling layers (e.g., max pooling), and layers that are completely connected (FC). The output of a model under different kernels and weights is determined with a loss function via forward propagation on a training dataset, and learnable parameters, i.e. kernels and weights, are modified according to the loss value through back propagation with gradient downward optimization algorithm.

The matrix on the right contains numbers between 0 and 255 each corresponding to the brightness of the pixels in the image on the left. The middle picture of both is overlaid.
Building Blocks For The CNN Architecture
There are several building blocks in the CNN architecture, such as convolution layers, pooling layers and fully connected layers. A typical architecture consists of repetitions of a stack of several layers of convolution and a layer of pooling, followed by one or more layers completely connected. The step of transforming input data into output via these layers is called forward propagation.
Convolution Layer
The convolution layer plays an important role in how CNN works, as suggested by the name. It forms the basic unit of a ConvNet where most of the computation is involved. The parameters of the layer focus around the use of learning kernels. For spatial dimensionality, however, these kernels are usually small, spreading over the whole dimension of input width. Once the information reaches a convolution layer, the layer converts every filter to provide a 2D activation map through the spatial dimensionality of the data. The output of neurons connected to local input regions can be checked via the convolution layer by measuring the scalar product between their weights and also the area connected to the volume of input. Neurons consisting of the same function map share the weight (parameter sharing) while reducing network complexity by keeping the number of parameters small. The rectified linear unit (commonly shortened to ReLU) attempts to use an activation function ‘ element wise ‘ like sigmoid at the activation output made by the previous layer. Convolution layers will significantly reduce the model’s complexity by optimizing its performance. Those are therefore optimized by three hyper parameters, the width, the phase and the setting of zero padding. Zero -padding is the straightforward method of padding the input border and an effective technique for providing additional control of the output volume dimensionality. We prefer to use the following formula to calculate the spatial dimensionality of the output of the convolution layers:
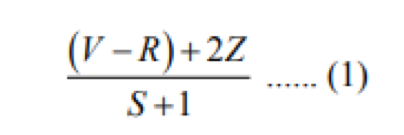
Where V is the size of the input volume (i.e. height x width x depth), R is the size of the receptive field, Z is the set of zero padding, and S refers to the stride.
The ConvNets are equipped with the Back propagation algorithm, which means that the backward pass often requires convolution with spatially flipped filters. The individual neuron within the output can reflect the gradient that could be lost throughout the depth, thereby upgrading only one set of weights as compared to each.
Pooling Layer
CNN includes not only layers of convolution, but also some pooling layers together. After a convolution layer there may be a pooling layer immediately. It indicates the convolution layers outputs are the inputs to the network’s pooling layers. Pooling operations cut the dimensions of the characteristic maps by victimizing other functions to summarize sub regions, such as taking the specific or maximum value. The goal of pooling layers is to cut the dimensionality of the data step by step, thus further reducing the number of parameters and also the complexity of the model’s process and thus controlling the issue of overfitting. Max pooling, average pooling, stochastic pooling, spectral pooling, spatial pyramid pooling, L2-norm pooling, and multi scale orderless pooling are a number of common pooling operations.
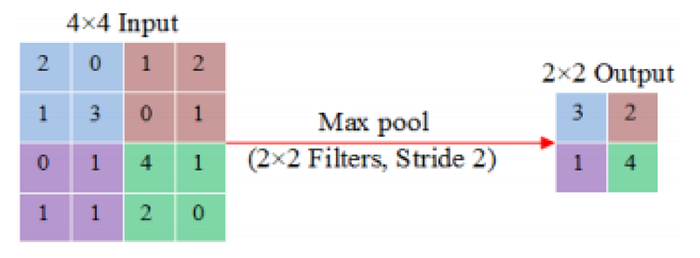
Within the input the pooling layer works over each activation map and scales its dimensionality using the function ‘ MAX. ‘ In most CNNs these are the available type of 2 x 2 dimensional kernel maxpooling layers applied with a 2 step on the spatial dimensions of the input and it scales up the activation map to 25 percent of the original size-while retaining the depth volume at its standard size. There are only two max-pooling approaches which are normally decided. The steps and filters of the pooling layers are typically set to 2 x 2 each, which can allow the layer to spread through the entire area of the input’s spatial dimensionality. In addition, overlapping pooling is also used where a kernel size set to 3 x 3 is set to 2. However, due to the dangerous nature of the pooling, having a kernel size greater than three can sometimes significantly reduce the model’s output. It is also necessary to know that CNN architectures may include general-pooling apart from the max-pooling. General pooling layers consist of pooling neurons ready to conduct a large number of traditional operations at the same time as L1/L2- standardization and average pooling.
Fully Connected Layers
The Fully Connected layer is designed just as their name implies: it is fully connected to the previous layer’s performance. Fully connected layers are usually used to connect to the output layer and create the desired number of outputs in the last stages of the CNN.
Common Convolutional Neural Network (CNN) Architectures
There are many reputed CNN architectures . Below are some of them
1. LeNet
LeNet was the most archetypal Convolution Neural Network established by Yann LeCun in 1990 and subsequently improved in 1998. The best known architecture in LeNet is the one that has been used to reading zip codes, digits, etc.
2. AlexNet
The first prominent CNN architecture is AlexNet, which popularizes in Computer Vision and the convolution neural network developed by Alex Krizhevsky, Ilya Sutskever, and Geoff Hinton. The Network had similar architecture to LeNet, but with all of it, it was the most important, most significant architecture. The layers of convolution packed together rather than the altering convolution and pooling layers as in LeNet.
3. ZF NET
After AlexNet, the winner of ILSVRC 2013 was this convolution neural network of Matthew Zeiler and Rob Fergus. It became known as ZFNet (Zeiler & Fergus Net short). It was an improvement on AlexNet by changing the architectural hyperparameters, primarily by increasing the dimensions of the convolution center layers and by establishing the smaller phase and filter size on the primary layer.
HOW ARTIFICIAL VISION CAN BE SOLVED USING CNN ( CONVOLUTION NEURAL NETWORK)
The first Convolution Neural Network — LeNet — 5 — was introduced in 1998 in a paper by bengio, Le Cun, Bottou and Haffner where it was able to classify digits from hand- written numbers.
Humans can spot and recognize patterns without having to re –learn the concept and identify objects no matter angle we look at. But the normal feed — forward neural network can’t do this. Ex : The image of a cat, what a computer actually sees is a numerical array where each value represents the color intensity of each pixel. However, Convolutional Neural Network is able to do so because it understands translation invariance — where it recognizes an object as an object, even when its appearance varies in some ways.
But how does it do that ?
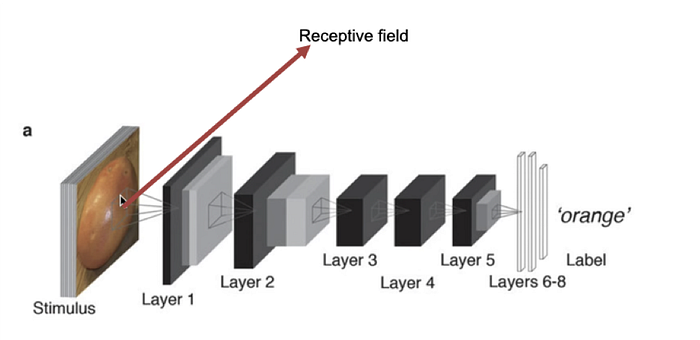
Some labeled images are feed into the model where the image pixel values are computed in the first layer of the network and then passed along the rest of the layer until it reaches the final layer where the network finally produces a predicted classification. The data fed into the convolutional networks are trained through supervised learning and back propagation where the predicted value will be compared to the correct output, where those that are wrongly classified will cause a large error gap and will cause the learning process to back propagate to make changes to the parameter in order to give out a more accurate outcome. The network goes back and forth, correcting itself until it achieves the satisfying output.
But there is a problem rising !! Deep neural network uses back propagation as well, so why is convolutional network any special ?
The convolutional network lies in the way the connections between the neurons are structured and the unique hidden layer architecture inspired by our very own visual data processing mechanism inside our visual cortex. And unlike deep neural networks, the layers in CNN are organized in 3 dimensions: width, height, and depth (which can be represented in 3-dimensional matrix).
The most important properties of the convolutional network regardless of how many layers there are — that the whole system of CNN is composed of only two major parts:
· FeatureExtraction:
During FE, the network will perform a series of convolutions (think of convolution as combining two things together to give certain output) and pooling operations where features are detected. This is the part where certain feature such as the cat’s ear, paw, fur color is recognized.
· Classification:
Here the fully connected layers on top of these extracted features should serve as a classifier. They must give a probability on the image for the object being what the algorithm predicts it to be.
Common Algorithms Used In Convolution Neural Network
Deep learning concept and algorithm play a pivotal role in solving various complicated problems such as playing games, forecasting economic future values; detecting objects in images. It could break through the bottle neck in conventional methods of neural networks and artificial intelligence.
So, lets compare two influential deep learning algorithms in image processing and object detection, that is, Mask — R — CNN and Yolo. Detection tasks are now becoming more complex as they come up with numerous variations in the expected appearance, structure, attire, logic, and fluid nature of their behaviour. So, therefore the main objective of the present work is to compare the performance of YOLO and Mask — R –CNN, That exposes Mask — R –CNN’s inability to detect tiny human figures among other prominent human images, and demonstrates YOLO’s success in detecting most of the human figures in a higher-precision image.
Mask R –CNN
Mask R –CNN (regional convolutional neural network ) is the extended version of Faster R-CNN. Mask R –CNN has same two stages : the first phase scrutinizes the picture and produces proposals. In the second phase it categorizes the proposals and results in bounding boxes and masks. Feature Pyramid Network (FPN) and a ResNet101 are used as backbone architecture in Mask R-CNN. To anticipate segmentation masks on each Region of Interest (RoI) a branch is added which is used for classification and bounding box regression simultaneously with the existing branch. ROI pooling denotes cropping and re –sizing a part of a feature map to a rigid size. Moreover, pixel- to — pixel alignment is the key elements of Mask R — CNN which is absent in Fast/Faster R-CNN. For particular instance of an object in the picture, the model produces bounding boxes and segmentation masks.
YOLO
“You Only Look Once” (YOLO) is a stage object detector capable of predicting a certain object on each region of the feature maps deprived of the process of classification of the cascaded site. YOLO employs a particular CNN network and applies bounding boxes to classify and locate the object. It splits the picture into a grid of S x S; S ∈ ℤ +. It would be the object if an object’s focal point swoops a grid cell. YOLO being a single stage detection system, YOLO is immensely fast and is being used in real time for object detection.
Conclusion
Both Mask R-CNN and YOLO can detect object. Mask R-CNN will take advantage of additional data even if that data is unlabeled. Mask R-CNN is also capable for instance segmentation. It can be used in Human pose approximation. The key findings of this study can be concise as :
Comparing to YOLO, Mask R-CNN takes more time for detection.
Moreover, in few cases Mask R-CNN was found unable to detect human figures, one instance has been presented, whereas YOLO is capable of detecting all types of human figures.
YOLO can be used in any kind of object detection in real time and can be considered as the better model between the mentioned two.
References
· Artem Oppermann, “Artificial Intelligence vs. Machine Learning vs. Deep Learning”, https://www.deeplearning-academy.com/p/ai-wiki-machine-learning-vs-deep-learning, 29th September 2019
· Mariner –USA, “Deep Learning vs Traditional Machine Vision”, https://mariner-usa.com/deep-learning-vs-traditional-machine-vision/, 4th November 2019
· Aravind Pai , “CNN vs. RNN vs. ANN — Analyzing 3 Types of Neural Networks in Deep Learning”, https://www.analyticsvidhya.com/blog/2020/02/cnn-vs-rnn-vs-mlp-analyzing-3-types-of-neural-networks-in-deep-learning/, 17th February, 2020
· Rikiya Yamashita, “Convolutional neural networks : an overview and application in radiology “,https://link.springer.com/article/10.1007/s13244-018-0639-9, 22nd June 2018
· Kates Reyes, “What is Deep Learning and How Does Deep Learning Work”, https://www.simplilearn.com/what-is-deep-learning-article, 8th February 2020
· Shadman Sakib, “An Overview of Convolutional Neural Network : Its Architecture and Applications”, https://www.researchgate.net/publication/329220700_An_Overview_of_Convolutional_Neural_Network_Its_Architecture_and_Applications, November 2018
· Puttatida Mahapattanakul, “From Human Vision to Computer Vision — Convolutional Neural Network (Part ¾)”, https://becominghuman.ai/from-human-vision-to-computer-vision-convolutional-neural-network-part3-4-24b55ffa7045, 11th November 2019
· Abhineet Saxena , “Convolutional Neural Networks (CNNs) : An Illustrated Explanation”, https://blog.xrds.acm.org/2016/06/convolutional-neural-networks-cnns-illustrated-explanation/, 29th June 2016
