Software Architecture Patterns — Layered Architecture
Welcome back to the Software Architecture Patterns blog series. This is the 2nd chapter of the series and we’ll be talking about Layered Architecture Pattern. Hopefully, by the end of this post, you’ll have an understanding of this particular architecture pattern and how it can benefit you. So let’s get to it!
This blog goes as a series and we will be covering the following topics as the main chapters of the series.
- What is a Software Architecture Pattern
- Layered Architecture Pattern (this post)
- Microkernel Architecture Pattern
- Event Driven Architecture Pattern
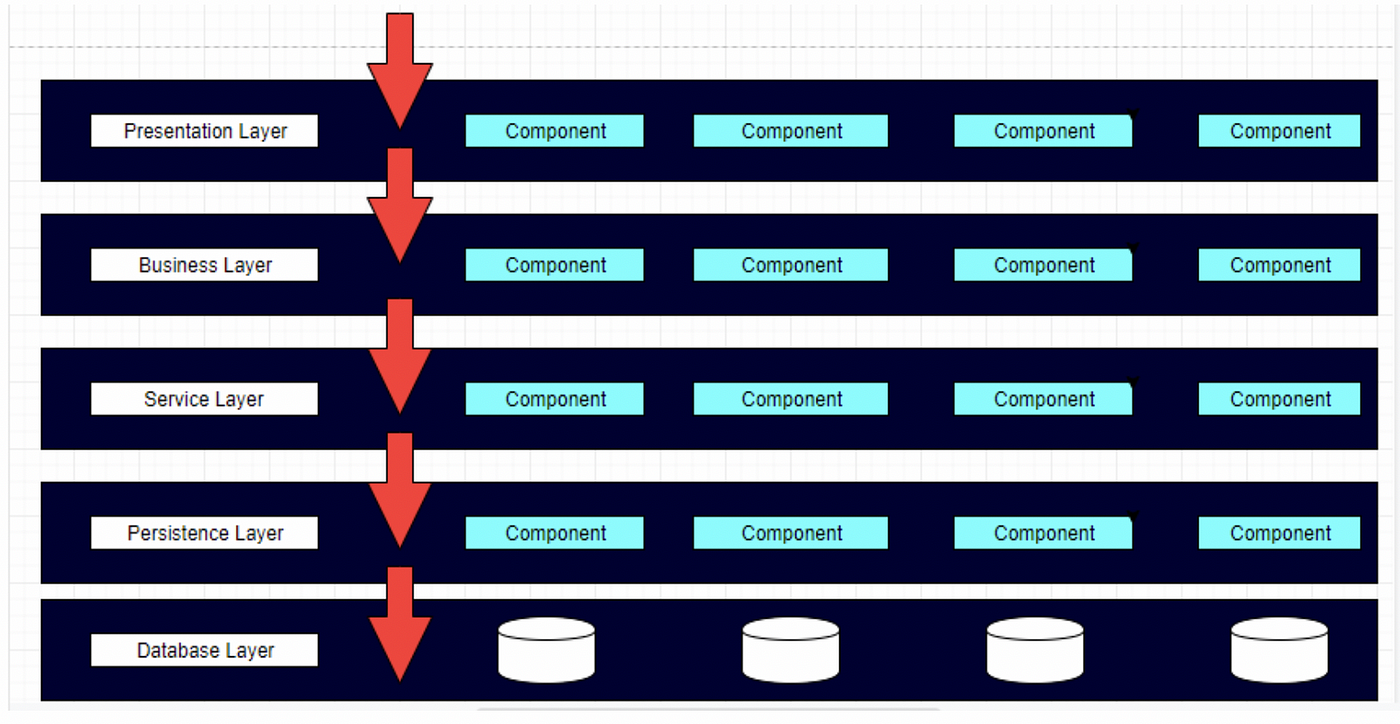
Layered architecture patterns are n-tiered patterns where the components are organized in horizontal layers. This is the traditional method for designing most software and is meant to be self-independent. This means that all the components are interconnected but do not depend on each other.

There are four layers in this architecture where each layer has a connection between modularity and component within them. From top to bottom, they are:
The presentation layer : It contains all categories related to the presentation layer.
The business layer : It contains business logic.
The persistence layer : It’s used for handling functions like object-relational mapping
The database layer : This is where all the data is stored.
In this instance the layers are closed, meaning a request must go through all layers from top to bottom. There are two reasons for this, one being that all ‘similar’ components are together and the other reason is that it provides layers of isolation.
To elaborate, having ‘similar’ components together means that everything relevant to a certain layer, stays in that single layer. This allows for a clean separation between types of components and also helps gather similar programming code together in one location. By isolating the layers, they become independent from one another. Thus if, for example, we want to change the database from an Oracle server to a SQL server, this will cause a big impact on the database layer but that won’t impact any other layers. Likewise, suppose that you have a custom written business layer and want to change it for a business rules engine. The change won’t affect other layers if we have a well-defined layered architecture.
The layered architecture pattern can be modified to have additional layers aside from the ones mentioned. This is known as hybrid layered architecture. For example, there can be a service layer between the business layer and the persistence layer. However, this is not an ideal scenario as now the business layer must go through the service layer to get to the persistence layer. This request doesn’t gain any value by going through the service layer. We call this an architecture sinkhole anti-pattern. Requests pass through layers with little or no logic performed in each layer.
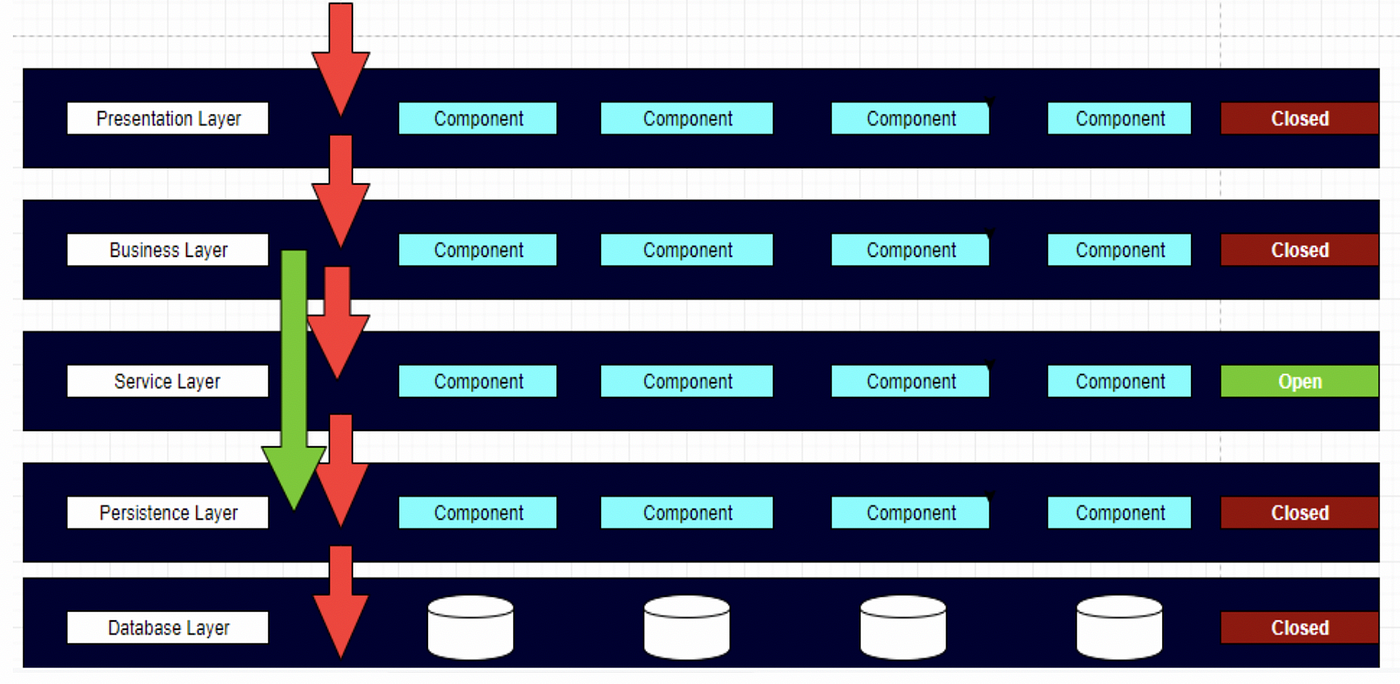
The only way this can be solved is by making the optional layer an open layer. This means that if the optional layer adds any value to the request being sent, then the request goes through it. If not, then it will simply bypass this layer and go to the relevant layer after. This can be seen in the above diagram where the request bypasses the service layer and moves through from the business layer to the persistence layer.
Note however that by having open layers, we take away the benefits of having isolated layers. If we wanted to swap out the persistence layer, we would have to consider the open service layer as well as the business layer. Both these layers are now coupled to the persistence layer. Thus while it is very easy to add open layers to a system, it should not be allowed to happen. We must try to solve problems without compromising the architecture.
Conclusion
The layered architecture is the simplest form of software architectural pattern. If you are going to design a rudimentary application where the user count is very low ( < 100–200 ) and you are sure that there won’t be too much requirement changes after you go live, this is the best software architecture pattern to use. The implementation cost for this architecture pattern is very minimal compared to other patterns.
The following is a pro — cons analysis of layered architecture pattern.
Pros
It is easy to test as components belong to specific layers. As such, they can be tested separately.
It is simple and easy to implement because naturally, most applications work in layers.
Cons
Although changes can be done to a particular layer, it is not easy because the application is a singular unit. Also, the coupling between layers tends to make it harder. This also makes it difficult to scale.
It must be deployed as a singular unit thus a change to a particular layer means the whole system must be redeployed.
The larger is it, the more resources it requires for requests to go through multiple layers and thus will cause performance issues.
Stay tuned to this blog series as we will be discussing how to apply the most common software architecture patterns. The next post of this series will discuss the Microkernel Architecture pattern.
If you have any queries/concerns, then you can drop me an email or send me a message on LinkedIn or Twitter. I’m just a message away :)
